


 Gradial
Gradial  PEGA
PEGA HCP data fragmentation in pharma: what it costs you and how Salesforce Data Cloud fixes the root cause
Jun 24, 2026 | 8 min read
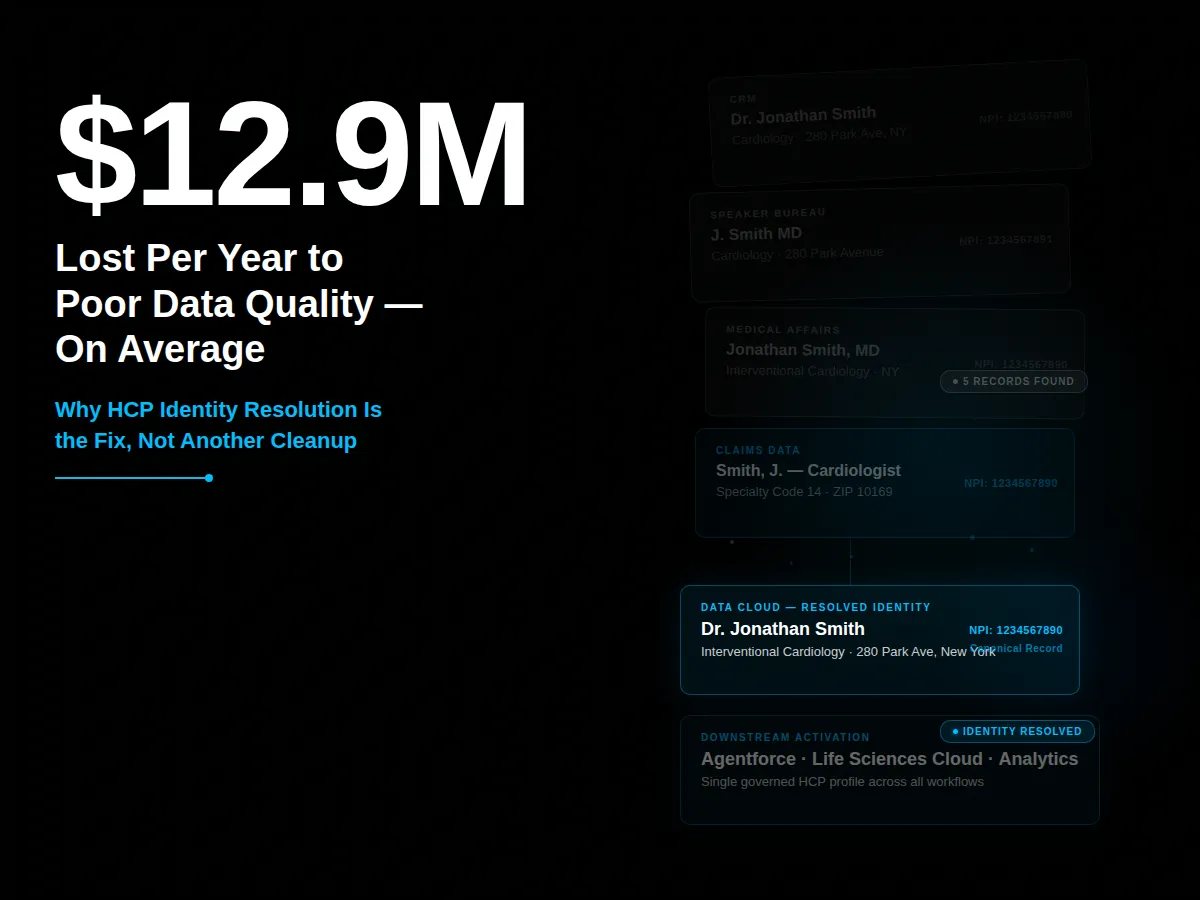
Most pharma organizations don’t have an HCP data problem. They have an HCP identity problem. The data exists in the CRM, the claims systems, the speaker bureau, the medical affairs platform, and the sample management tool. The problem is that each of those systems has its own version of the same provider, with its own identifiers and its own definition of current. Salesforce Data Cloud fixes that at the architecture layer, not the spreadsheet layer. But only when the identity resolution, survivorship rules, and data provenance are designed correctly first.
Ask any commercial operations leader how many systems contain HCP data. Most will pause before answering. Seven is common. Ten isn’t unusual. The same cardiologist can exist as “Dr. Jonathan Smith” in the CRM, “J. Smith MD” in the speaker bureau platform, and an NPI-linked record with a different mailing address in the medical affairs tool. Nobody knowingly built it that way. It accumulated one system at a time, each solving a specific workflow without asking whether provider identity was already solved somewhere else.
Gartner puts the average cost of poor data quality at $12.9 million per organization per year. (Gartner, Data Quality Topics) In pharma, that compounds fast: field teams working from stale records, segmentation pulling the wrong providers into campaigns, and AI projects that fail before they get started because the data underneath them is inconsistent.
Why do pharma organizations end up with five versions of the same HCP?
The fragmentation almost always traces to a decision made early in each system’s life: HCP data got treated as a local application problem instead of a shared identity problem. When the CRM team needed clean HCP records, they cleaned them for the CRM. When the speaker bureau needed current affiliations, operations pulled and fixed the data for the bureau. When a new market access tool went live, it imported HCP records from whatever export was available.
None of those decisions were wrong in isolation. Each solved a real problem. But collectively, they produced an architecture where the same provider exists in multiple systems under multiple identifiers, with no agreed-upon source of truth for which system wins when they disagree. Is the NPI registry authoritative for specialty? Is the CRM authoritative for engagement preference? Is a third-party data provider authoritative for affiliation? Most organizations haven’t answered those questions at the architecture level, so each system answers them differently.
This is what Jeff Sumption, CI Digital’s Salesforce Solution Architect, describes as treating an architecture problem as an application problem. A connected pharma architecture requires answering those identity questions once, at the foundation level, not for each system individually.
What does HCP data fragmentation actually cost?
The direct cost shows up in reconciliation time: operations staff manually comparing records across systems, field teams emailing each other about which version of an HCP’s address is current, marketing holding a campaign because the segmentation file doesn’t match the CRM.
The indirect cost is larger. Fragmented HCP data is the reason AI projects stall in pharma more often than in other industries. Gartner predicts that 60% of AI projects lacking AI-ready data will be abandoned through 2026. (Gartner, February 2025) AI doesn’t work around five conflicting versions of the same provider. It fails on them.
There’s also a strategic cost. When field teams don’t trust the CRM data, they build workarounds: spreadsheets, shared drives, personal contact lists. Every next-best-action recommendation and every segmentation model built on top of the official data inherits its unreliability.
Why doesn’t cleaning the data fix it?
Data cleaning fixes the problem temporarily and locally. Cleaning for a specific campaign removes duplicates for that campaign. A territory realignment cleanup fixes records for that alignment. A regulatory submission reconciliation produces accurate records for that submission. None of those operations define how new HCP data gets created, validated, and maintained going forward.
Six months after the cleanup, the same provider reappears in two systems with two different NPI associations because neither system knows which one is authoritative. The duplication isn’t a data entry failure. It’s a governance failure: no one defined which system creates the canonical HCP record, which sources are authoritative for which fields, and what happens when sources disagree.
This is the distinction between deduplication and identity resolution. Deduplication removes extra copies of a record. Identity resolution answers what makes two records refer to the same real-world entity, which source wins for each field, and how changes in one system propagate to the others. Most pharma CRM platforms handle deduplication. Identity resolution requires a different architectural layer.
What does identity resolution actually require?
Identity resolution for HCP data requires three components that most pharma organizations don’t have in place.
The first is a canonical identity model: the organization can answer with confidence whether “Dr. Jonathan Smith” in the CRM and “J. Smith MD” in the claims system are the same person. That answer comes from NPI matching, address comparison, specialty alignment, and affiliation cross-referencing. Rules, not just a lookup table.
The second is data provenance. Every field in the HCP profile should carry metadata: which system contributed this value, when it was updated, and why it was chosen over a competing value from another source.
The third is survivorship rules. Not every source wins for every field. The NPI registry might be authoritative for license status. The CRM might be more current for engagement preference. A third-party provider might be more accurate for current hospital affiliations. Survivorship rules define which source wins for each field and under what conditions a lower-priority source can override the default.
What does Salesforce Data Cloud do differently at the identity layer?
Salesforce Data Cloud doesn’t replace the systems that hold HCP data. It creates a unified data layer on top of them, where identity resolution, provenance, survivorship, and activation happen across all connected sources. This is why AI use cases in pharma work better with Data Cloud as the foundation: the model operates against a governed, unified HCP profile, not five competing records.
In practice, a field rep’s CRM view pulls from a resolved identity that incorporates affiliation updates from a third-party provider, engagement history from the interaction platform, and prescribing signals from claims data. When an affiliation changes in the third-party source, it doesn’t create a new duplicate. It updates the canonical record per the survivorship rules already defined.
How is this different from what Salesforce CRM already does?
Salesforce CRM stores and manages relationship records. It tracks interactions, tasks, opportunities, and engagement history for HCPs that a user has created or imported. It doesn’t resolve identity across external systems, apply survivorship rules across competing data sources, or unify signals from claims, affiliations, and third-party data into a single governed profile.
Data Cloud sits at a different layer of the architecture. The CRM is where field teams work with HCP relationships. Data Cloud is where those HCP identities get defined, resolved, and governed so the CRM always works from a clean, current, trusted record.
Where does a pharma team actually start?
Start with the data model, not the technology. Before deploying Data Cloud or running an identity resolution project, map which systems hold HCP data, which is authoritative for which fields, and what rules currently govern survivorship when sources conflict. Most organizations discover they haven’t answered those questions, which is why every previous cleanup effort produced only temporary results.
The mapping exercise surfaces which fields are contested across systems, which sources are most current for specific data types, and where governance gaps exist. Once that picture is clear, the technology decisions become straightforward. Data Cloud’s configuration reflects governance decisions already made, not the other way around.
CI Digital’s Salesforce team works through this diagnostic with pharma clients at the start of every Data Cloud and Life Sciences Cloud engagement. Talk to our Salesforce team about where to start.
Frequently asked questions
What is HCP data fragmentation in pharma?
HCP data fragmentation means the same healthcare provider exists as multiple, inconsistent records across different systems: CRM, claims, speaker bureau, medical affairs platforms, and third-party data providers. Each system has its own version of the provider’s name, affiliations, and contact information, with no agreed-upon source of truth. The result is field teams working from conflicting data, broken segmentation, and AI projects that fail at the data layer.
What is HCP identity resolution and how is it different from deduplication?
Deduplication removes extra copies of the same record within a single system. HCP identity resolution answers a harder question: across systems with different identifiers, which records refer to the same real-world provider, which source is authoritative for each field, and how changes in one system update the others. Salesforce Data Cloud handles identity resolution across systems. CRM deduplication tools handle only within-system duplicates.
What does Salesforce Data Cloud do for HCP data specifically?
Salesforce Data Cloud creates a unified HCP identity layer that connects records across CRM, claims, affiliations, and third-party data sources. It applies identity resolution algorithms and survivorship rules to produce a single, governed HCP profile. That profile feeds into Salesforce Life Sciences Cloud, Agentforce, and analytics tools so every downstream workflow runs from one consistent view of the provider.
Why do pharma HCP data cleaning projects keep failing?
Because they solve a data quality problem without solving the data architecture problem. A cleanup removes duplicates for a specific use case but doesn’t define which system is authoritative for new records going forward or what governance rules prevent the same duplication from recurring. Identity resolution at the architecture level is the permanent fix. Campaign-level cleaning is a temporary patch.
Author

Jeff Sumption

Share this article
Subject Matter Expert
Jeff Sumption
Salesforce Solution Architect
Speak With Our Team
Share this article


